2023 年 12 月: AWS CloudWatch のログを pandas で解析し、エラーの状況を可視化する(terapyon)¶
寺田 学@terapyonです。2023 年 12 月の「Python Monthly Topics」は、CloudWatch Logs に蓄積したログを pandas で状況を確認したり、可視化する方法を解説します。
目的・モチベーション¶
AWS でサーバの運用を行っていると、さまざまなログが CloudWatch Logs に保存されます。保存されたログから、動作状況の確認やエラーなどを特定、傾向を掴むために外部のツールと組み合わせることがあります。
pandas という Python でデータ分析を行なっている方には馴染みのあるツールを使ってログを処理できます。 さらに、Python コードで実行できることで、定期的な実行もできます。
本記事を読む上での予備知識¶
実際の加工や可視化を行う前に、本記事の前提となる用語の解説やツールの説明をします。
AWS CloudWatch Logs とは¶
パブリッククラウドである、Amazon Web Service(AWS)のマネージドサービスを使っていると、「CloudWatch Logs」 というログ収集機能でログが保存されます。例えば、 「AWS Lambda」 や 今回紹介する 「AWS WAF」 などの動作ログやエラーログが CloudWatch Logs に保存されます。
よくある分析方法¶
CloudWatch Logs でよくあるログ分析方法を説明します。
Web コンソールで見る
CloudWatch Logs では、AWS Web コンソール経由で、ほぼリアルタイムでログを閲覧できたり、フィルタフィングしたりする機能があります。 しかし、詳細の分析をするには AWS Web コンソールでは不十分なことがあります。
CloudWatch Logs Insights 機能を使う
Web コンソールから、 「Logs Insights」 を利用することで、ある程度の分析や傾向を掴むことができます。
S3 にデータ転送し、複数ファイルをダウンロードして加工
AWS のストレージサービスである、 「S3」 にログデータを転送し、ローカル PC にダウンロードすることができます。 ただし、何かしらのツールでデータを S3 に転送する処理を実行する必要があります。 また、CloudWatch のログは時間によって自動的に分割されるため、ひと手間作業しないとログをまとめて分析することができません。
Amazon Athena に連携して分析
AWS のマネージドサービスである 「Amazon Athena」 を利用するという方法があります。 常にログの監視を行っている場合には、導入されているケースもあるかと思います。
追加の費用が必要だったり、事前の設定が必要というところがネックになる場合があります。
pandas での時系列データの扱い¶
pandas は、Python のサードパーティ製パッケージで、データ分析を行う上でよく使われているライブラリです。 pandas には、データ分析を行う上で、豊富な機能が備わっています。 特に 「DataFrame」 というデータ形式で、二次元のデータを Index 付きで扱います。
pandas では時系列の Index を付与した DataFrame が作成できるので、ログデータを分析しやすくできます。 時系列データの処理ができるので、時間を指定しての検索や、時間ごとの統計的な分析、可視化ができます。
AWS CloudWatch Logs におけるログデータの扱いが大変¶
CloudWatch Logs のデータは、一般のログデータと違い、JSON 形式で扱われることがあります。さらに、テキスト形式で扱われる場合もあり、その時にはログ内の改行によってレコードが分割されることがあります。また、ダウンロードしたファイルは複数ファイルに分かれていて、ダウンロード時には圧縮されていることがあり多種多様な形式になっています。
JSON で保存される WAF のログの例
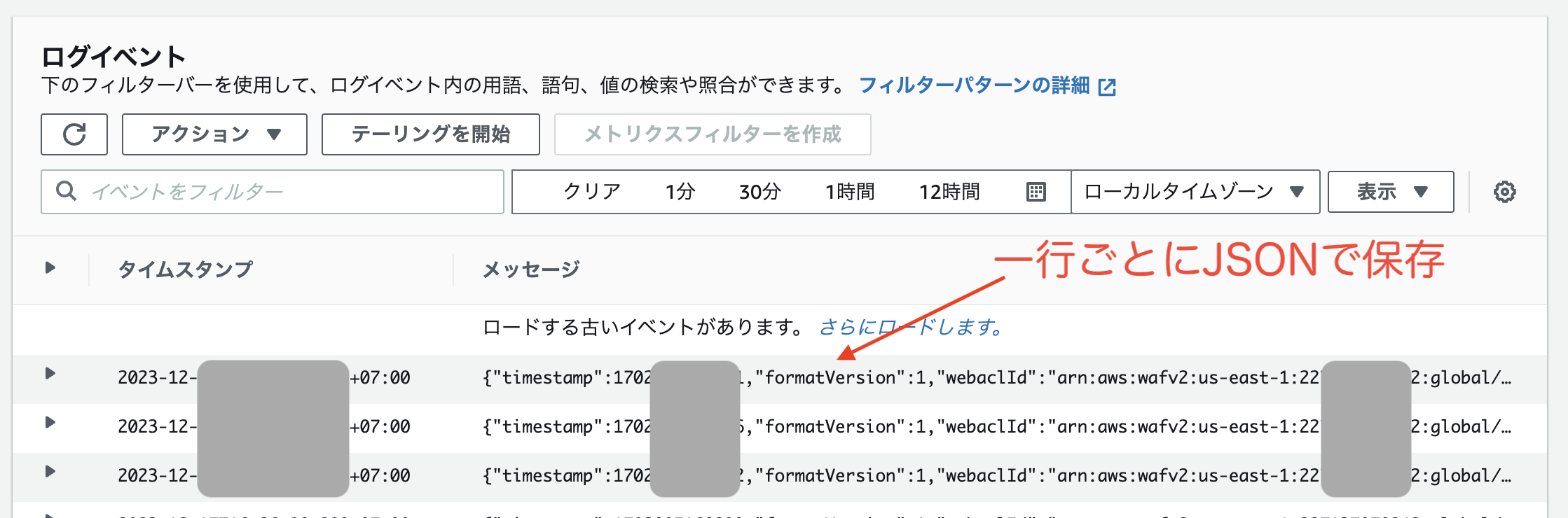
テキストで保存される Lambda のログの例
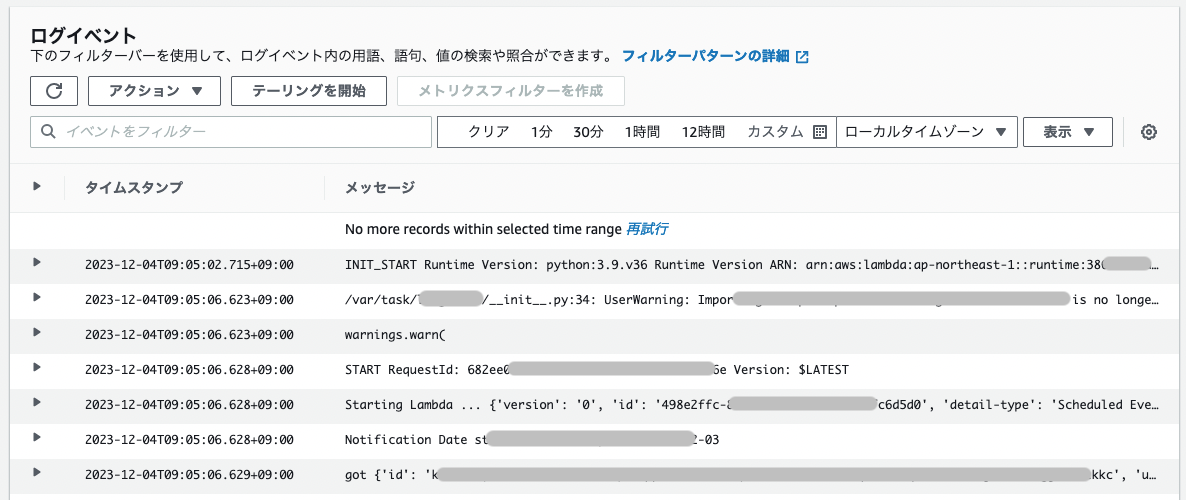
Python の標準ライブラリを使ってログデータの解析を行うことはできますが、この記事では CloudWatch Logs を簡単に扱うためのツールを紹介します。
AWS SDK for pandas のインストールと環境の準備¶
AWS SDK for pandas は、AWS が開発し公開しているオープンソースのライブラリで、CloudWatch Logs や Athena、S3 データなどの AWS のリソースを、pandas で効率的に扱うことができます。
項目 |
内容 |
|---|---|
ライブラリ名 |
AWS SDK for pandas (awswrangler) |
開発元 |
AWS |
ライセンス |
Apache License 2.0 |
Python バージョン |
3.8 以上 |
公式サイト |
|
PyPI |
|
github |
|
執筆時点のバージョン |
3.4.2 |
このツールでは、以下に対応しています。(公式サイトより)
Athena, Glue, Redshift, Timestream, OpenSearch, Neptune, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretManager, PostgreSQL, MySQL, SQLServer and S3 (Parquet, CSV, JSON and EXCEL)
今回は、CloudWatch Logs の解析に着目して紹介します。
具体的には、CloudWatch Logs のログを読み込む、 awswrangler.cloudwatch.read_logs 関数があります。 この関数を使用することで、CloudWatch Logs のログを pandas の DataFrame に変換できます。詳細については後述します。
インストールと基本設定¶
インストール方法は以下の通りです。
pip install awswrangler
awswrangler をインストールすると、同時に pandas がインストールされます。また、AWS SDK for Python である boto3 も同時にインストールさます。
この記事で紹介するコードを JupyterLab で実行可能にし、可視化するためにグラフライブラリの Matplotlib もインストールしてください。 JupyterLab は Web ブラウザで対話型にプログラムを実行できる環境です。
pip install jupyterlab matplotlib
awswrangler で、cloudwatch.read_logs を使ってログを取得するには、 AWS のクレデンシャル設定 が必要です。
AWS のクレデンシャル設定の前に、AWS IAM にて CloudWatch Logs の読み取り権限を持つユーザを作ります。IAM ユーザに幅広い権限を付けると不用意な操作ができるため、専用のユーザを作ることをお勧めします。
IAM ユーザの設定情報
項目 |
内容 |
|---|---|
ユーザ名 |
gihyo-monthly-test (任意の名前) |
マネジメントコンソール |
ユーザーアクセスを提供しない (チェックなし) |
ポリシー |
CloudWatchLogsReadOnlyAccess |
アクセスキー |
作成する |
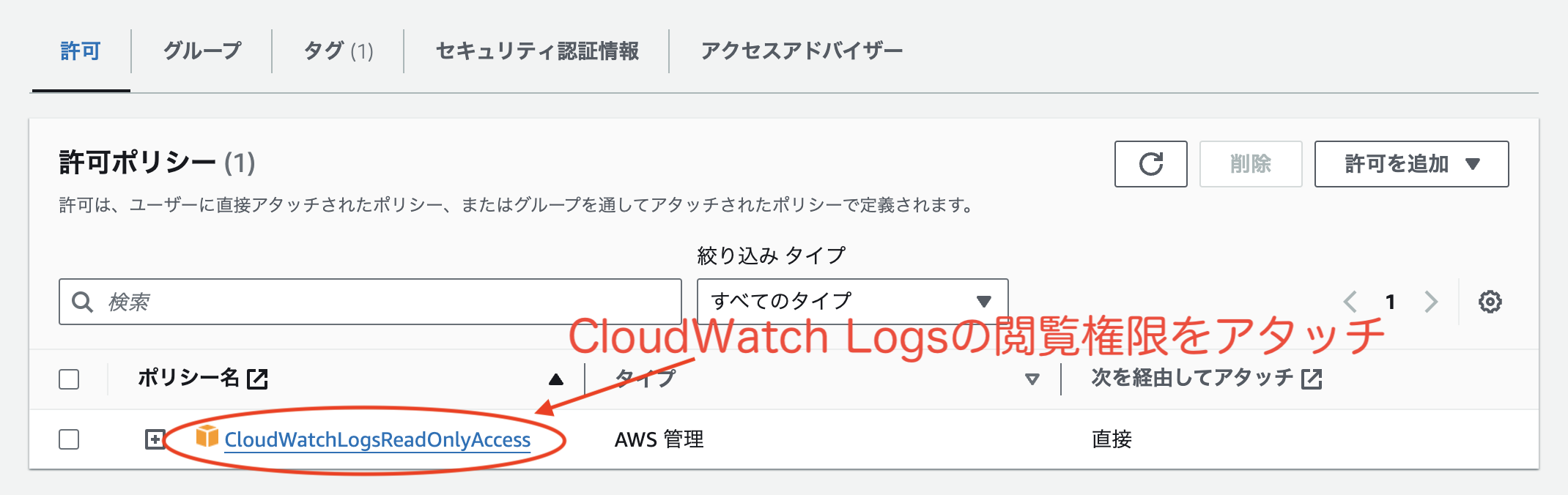
IAM ユーザの作成方法の詳細は、IAM 公式ドキュメント 又は他の参考資料をご確認ください。
IAM ユーザを作成する時に、「アクセスキー」と「シークレットアクセスキー」が作成時のみ画面に表示されます。 これらのキーは後ほどログを取得する際に利用しますので、大切に保管してください。
AWS プロファイルを手元の PC に設定する方法もありますが、今回はプロファイルを生成せずに環境変数でコードに渡す方法で説明します。 AWS プロファイルの設定を行いたい場合は、 AWS 公式ドキュメント(Configure the AWS CLI) を確認してください。
環境変数への登録と確認¶
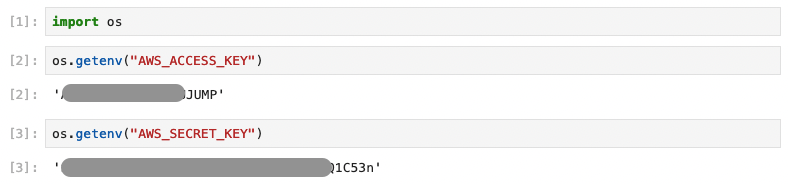
「アクセスキー」と「シークレットアクセスキー」を環境変数に設定します。
$ export AWS_ACCESS_KEY=****************JUMP # 作成したアクセスキー
$ export AWS_SECRET_KEY=**************************1C53n # 作成したアクセスキーののシークレット
$ jupyter lab
環境変数を設定して、JupyterLab を立ち上げ、Python の OS モジュールを使って環境変数の取得を行います。 以下のように設定した「アクセスキー」と「シークレットアクセスキー」が取得できたら、ここでの確認は完了となります。
cloudwatch.read_logs の基本的な使い方¶
ここでは、 cloudwatch.read_logs を使って AWS WAF のログを取得し、JSON 形式のログを DataFrame の列に展開し、必要な項目を抽出します。
ログのグループ名、期間、クエリーを設定して取得¶
CloudFront に設定したファイアウォール (AWS WAF) のログを取得します。 AWS WAF は、CloudFront の前面に配置できるファイアウォールです。今回の例では、ログインを伴う URL に対して IP アドレス制限をし、設定した IP 以外からのログインを禁止するように設定されています。
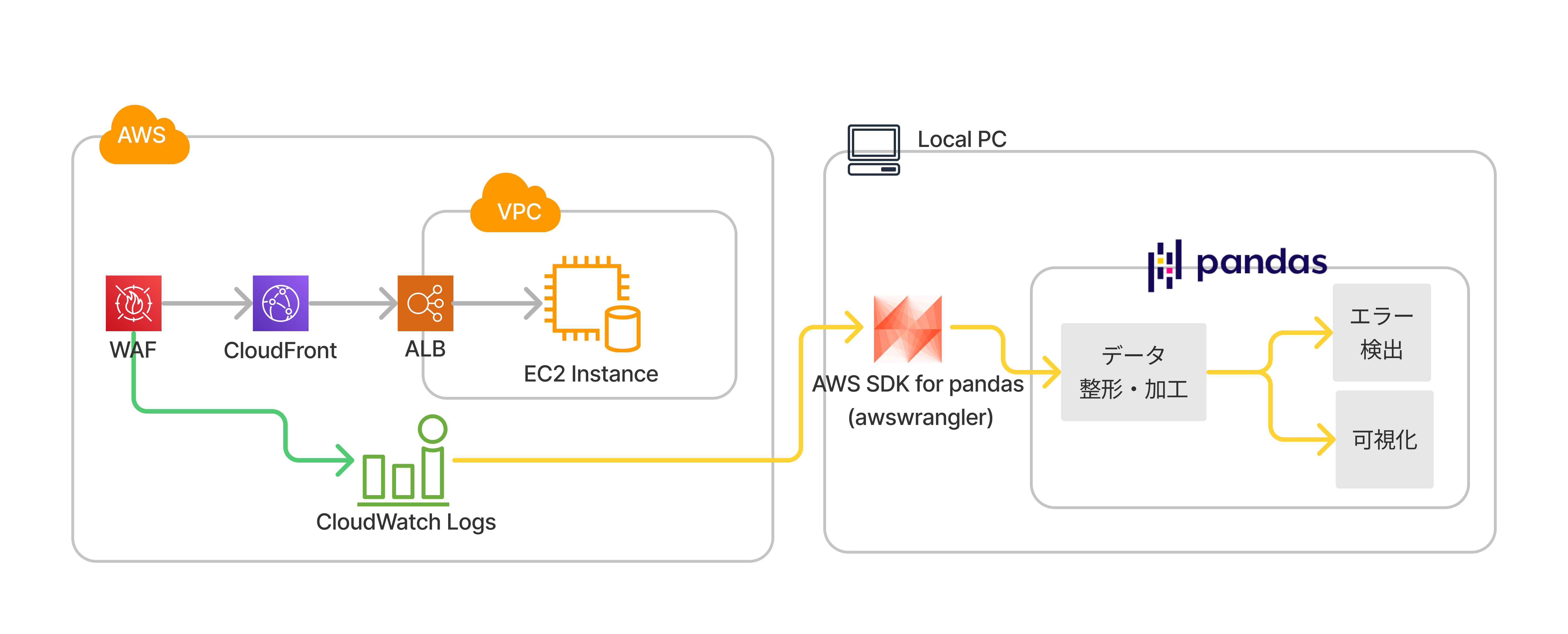
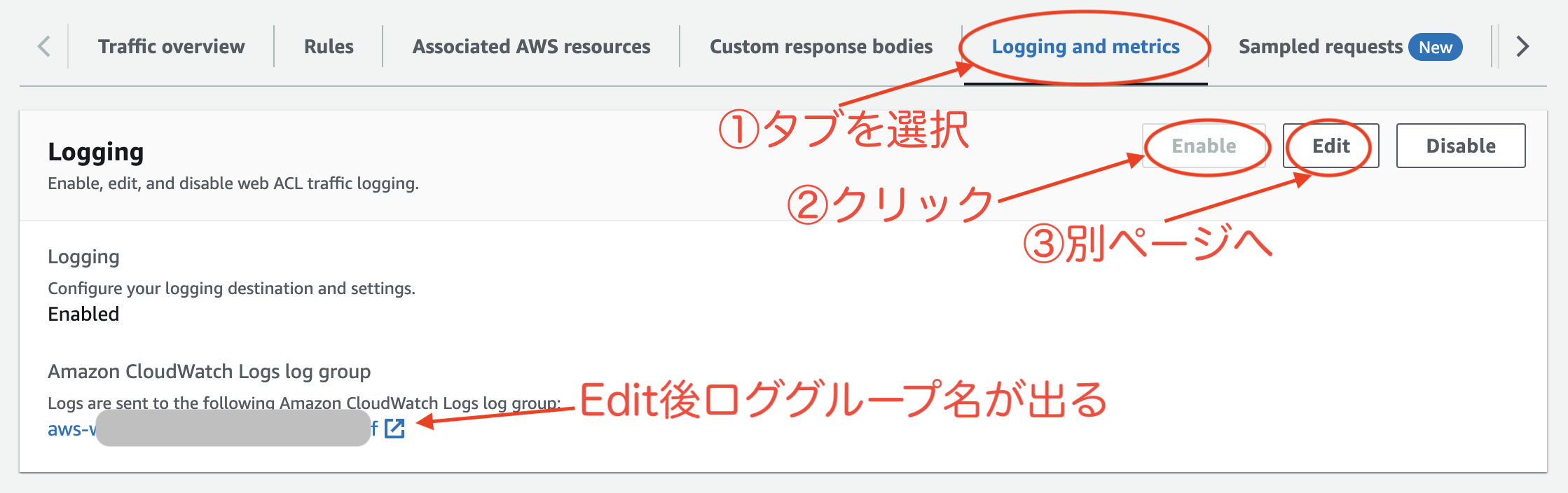
WAF のログを CloudWatch Logs に保存するには以下のように、AWS コンソールで設定をする必要があります。
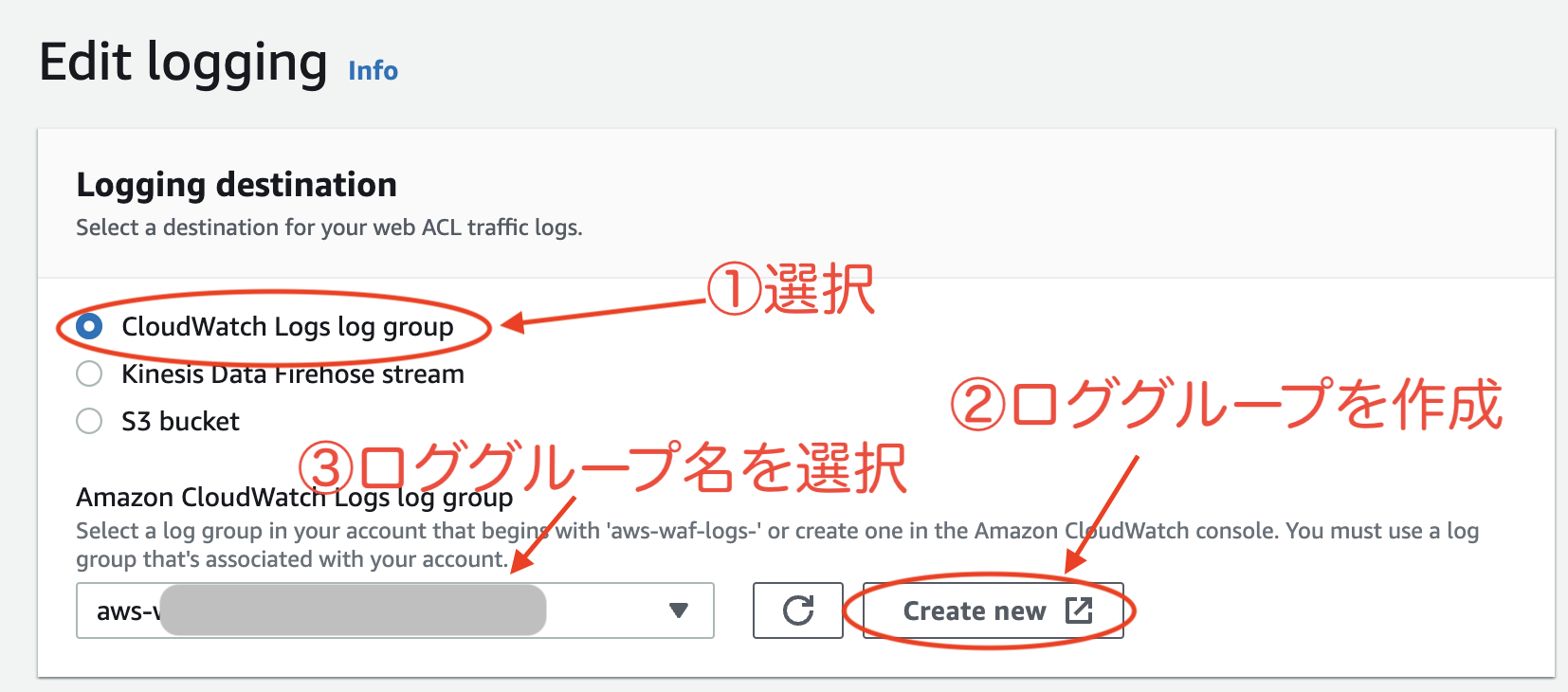
サンプル用に、ロググループ名は aws-waf-logs-XXXXXXXXXXXXXX-cf とします。
なお、今回のログは、CloudFront 関連のため、 リージョン us-east-1 に保存されています。
AWS コンソールで CloudWatch Logs を見ると以下のようになっています。
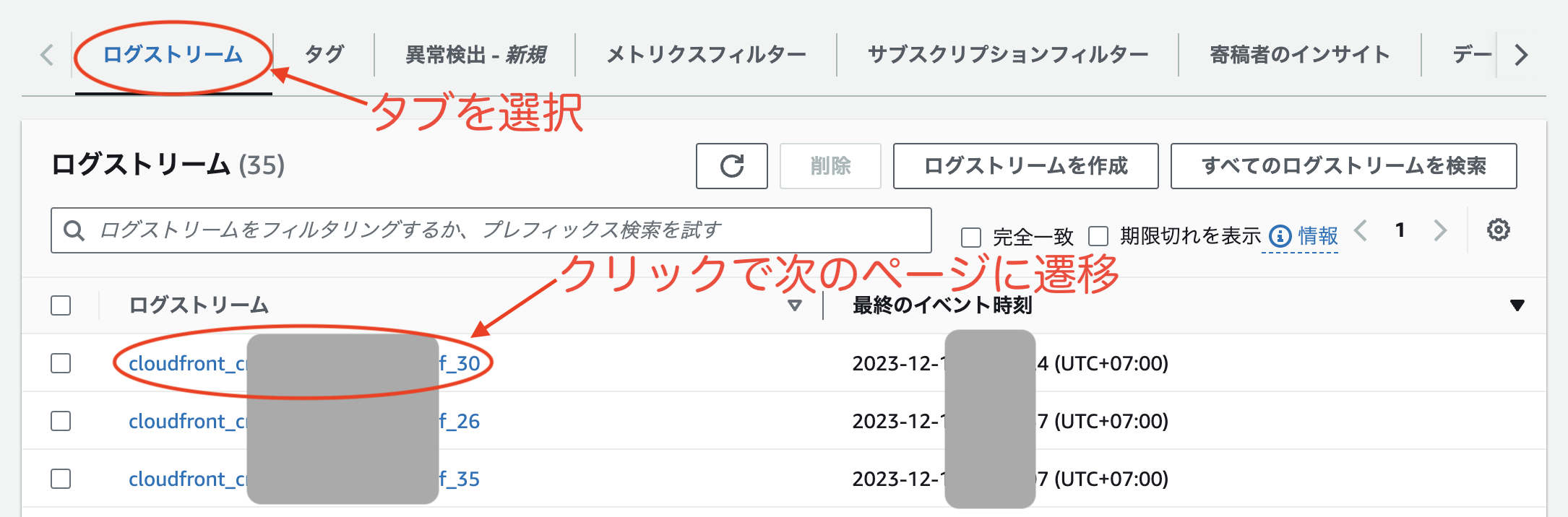
ここでは、Python コードで CloudWatch Logs のデータを取得し pandas の DataFrame に変換する方法を紹介します。
import os
from datetime import datetime
from zoneinfo import ZoneInfo
import awswrangler as wr
import boto3
ASIA_TOKYO = ZoneInfo("Asia/Tokyo") # タイムゾーンをJSTに設定
start = datetime(2023, 12, 4, 17, 55, 0, tzinfo=ASIA_TOKYO) # 2023年12月4日17時55分
end = datetime(2023, 12, 4, 18, 5, 0, tzinfo=ASIA_TOKYO) # 2023年12月4日18時05分
limit = 2000 # データ件数の上限
region_name = "us-east-1" # リージョン名
log_name = "aws-waf-logs-XXXXXXXXXXXXXX-cf" # ロググループ名
# boto3のセッションを作成
boto3_session = boto3.session.Session(
aws_access_key_id=os.getenv("AWS_ACCESS_KEY"),
aws_secret_access_key=os.getenv("AWS_SECRET_KEY"),
region_name=region_name,
)
# CloudWatch Logsからログを取得
df_waf_raw = wr.cloudwatch.read_logs(
log_group_names=[log_name], # ロググループ名
query="fields @timestamp, @message | sort @timestamp asc", # クエリ
limit=limit, # データ件数の上限
start_time=start, # 開始時刻
end_time=end, # 終了時刻
boto3_session=boto3_session, # boto3のセッション
)
print(df_waf_raw.shape) # (1338, 3)
このコードでは、2023 年 12 月 4 日 18 時の前後 5 分のログを取得しています。 ログを取得した結果、 1338 件のログが記録されていることがわかりました。
ログの取得に fields @timestamp, @message | sort @timestamp asc とクエリを設定しました。
これは、 timestamp と message のフィールドを取得し、 timestamp の昇順で取得する意味のクエリです。
AWS コンソールで見た通り、CloudWatch Logs にはタイムスタンプ(timestamp)とメッセージ(message)の組み合わせで保存されています。
CloudWatch Logs を検索するクエリ文法については次の公式サイトを参照してください。 CloudWatch logs クエリ文法
JSON 形式のログを展開¶
AWS WAF のログは、message 列が JSON 形式で以下のように出力されています。
{
"timestamp": 1701680117244,
"formatVersion": 1,
"webaclId": "arn:aws:wafv2:us-east-1:227xxxxxx242:global/webacl/xxxxxxxxxxxxcf/baed1c94-xxxxxxxxxxxxxxxx-55de7",
"terminatingRuleId": "Default_Action",
"terminatingRuleType": "REGULAR",
"action": "ALLOW",
"terminatingRuleMatchDetails": [],
"httpSourceName": "CF",
"httpSourceId": "EOXXXXXXXXXXXXMW",
"ruleGroupList": [],
"rateBasedRuleList": [],
"nonTerminatingMatchingRules": [],
"requestHeadersInserted": null,
"responseCodeSent": null,
"httpRequest": {
"clientIp": "52.xxx.xxx.247",
"country": "JP",
"headers": [
{ "name": "Host", "value": "www.xxxxxxx.jp" },
{ "name": "Accept-Encoding", "value": "gzip, deflate" },
{ "name": "User-Agent", "value": "xxxxxxxxxxxxxx" },
{ "name": "x-forwarded-for", "value": "10.x.xx.210, 127.0.0.1" },
{ "name": "x-forwarded-host", "value": "10.x.xx.75" },
{ "name": "Accept", "value": "application/json" },
{ "name": "Connection", "value": "close" }
],
"uri": "/",
"args": "",
"httpVersion": "HTTP/1.1",
"httpMethod": "GET",
"requestId": "pWxlfUPbfcztylxxxxxxxxxxxxxxxxxxxxxxxxxxyd4ll_CYPDXA=="
},
"ja3Fingerprint": "398430069xxxxxxxxxxxxxxxxxxxxx58d77"
}
このままでは pandas で解析しにくいので、pandas の json_normalize を用いて JSON のキーごとに DataFrame の列に分割します。
import pandas as pd
import json
df_waf = pd.json_normalize(df_waf_raw.loc[:, "message"].apply(lambda x: json.loads(x)))
print(df_waf.shape) # (1338, 25)
新たな DataFrame は、25 列になっていることがわかりました。
列名を出力して確認すると、以下のような情報が列に分割されていることがわかりました。
print(df_waf.columns)
Index(['timestamp', 'formatVersion', 'webaclId', 'terminatingRuleId',
'terminatingRuleType', 'action', 'terminatingRuleMatchDetails',
'httpSourceName', 'httpSourceId', 'ruleGroupList', 'rateBasedRuleList',
'nonTerminatingMatchingRules', 'requestHeadersInserted',
'responseCodeSent', 'ja3Fingerprint', 'httpRequest.clientIp',
'httpRequest.country', 'httpRequest.headers', 'httpRequest.uri',
'httpRequest.args', 'httpRequest.httpVersion', 'httpRequest.httpMethod',
'httpRequest.requestId', 'requestBodySize',
'requestBodySizeInspectedByWAF'],
dtype='object')
先頭の 2 行を出力します。
df_waf.head(2)

ここまでで、AWS WAF の CloudWatch ログを pandas の DataFrame に変換することができました。
message 内を必要な情報を抽出¶
ここでは、DataFrame を加工して解析を行うための準備を行います。
最初に、時系列データを扱うために、 timestamp 列を使ってインデックスに 「aware (タイムゾーン付き)」 な日時を設定します。
元のデータは、UTC 時間でタイムゾーンなしの日時が timestamp 列に入っています。DataFrame の dt アクセッサーから、 to_localize メソッドを呼び出し、aware に変換します。さらに、 dt アクセッサーから tz_convert を使って JST に変換しています。
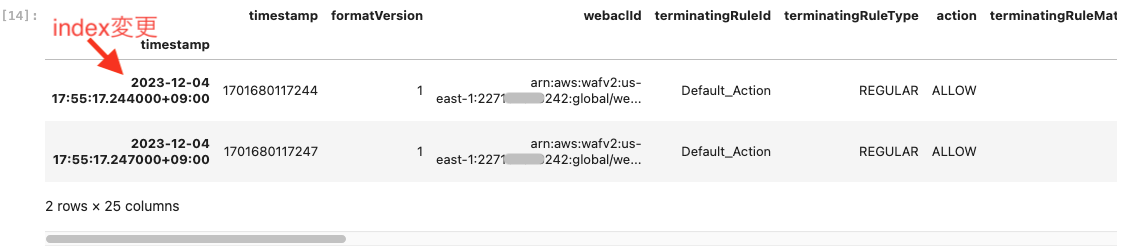
df_waf.index = df_waf_raw.iloc[:, 0].dt.tz_localize("UTC").dt.tz_convert("Asia/Tokyo")
データの先頭 2 行を出力して、インデックスがタイムゾーン付きの DataFrame になっていることを確認します。
df_waf.head(2)
次に、分析に利用したい列を抽出して、新たな DataFrame を生成します。
今回は、WAF のログから以下を抽出します。
action: WAF の動作 (ALLOW / BLOCK)
terminatingRuleId: WAF のルール
httpRequest.clientIp: 接続元 IP アドレス
httpRequest.uri: リクエスト URL
df = df_waf.loc[:, ["action", "terminatingRuleId", "httpRequest.clientIp", "httpRequest.uri"]]
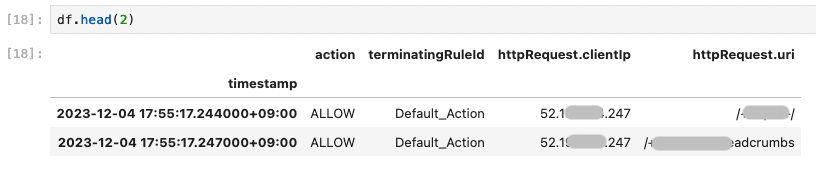
bool インデックスで目的の件数を調査¶
ここでは、WAF の動作で、 BLOCK された件数を調べたいと思います。
action 列に、 ALLOW または BLOCK が記録されています。BLOCK は何かしらのルールに従って、WAF(ファイアウォール)がアクセスを拒否したものです。BLOCK された件数が多いということは、何かしらの攻撃を受けているか、ルールが厳しすぎてアクセスできない場合が多いことを示します。
df_blocked = df.loc[df.loc[:, "action"] == "BLOCK", :]
print(df_blocked.shape) # (4, 4)
今回は、10 分間に 4 件の BLOCK が発生したことがわかりました。
pandas の bool インデックスの機能を使い、 action 列が BLOCK のものを抽出した df_blocked を作りました。
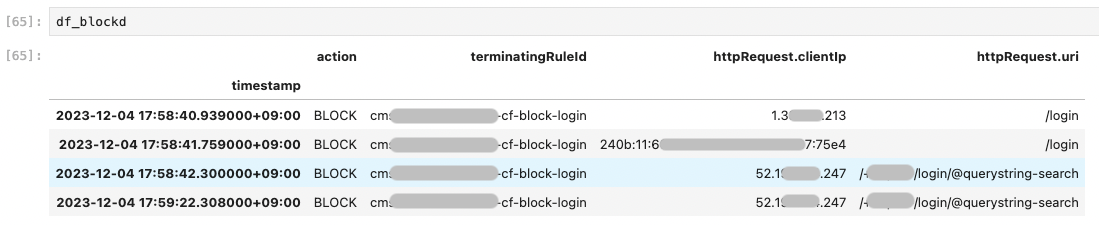
適切に BLOCK されているのであれば問題ありませんが、本来アクセスできるはずなのに、何かしらの要因で BLOCK されたものを調べたい時には、この様に BLOCK されているログのみを抽出します。
抽出したログを参照して、適用された WAF のルール、接続元 IP アドレスや URL などを確認することで、原因を特定していきます。
今回は BLOCK された件数が 4 件と少なかったので全データを確認することができました。件数が多い場合や傾向を知りたい場合は次のセクションの「ログの集計と可視化、分析方法」を参照してください。
ログの集計と可視化、分析方法¶
ここでは、pandas を利用してログから、 BLOCK された件数を集計したり可視化する方法について解説します。
1 分単位で BLOCK された状況を確認¶
今回は 10 分間のログデータを使っているので、1 分単位で ALLOW/BLOCK の件数を確認します。
df["round_min"] = df.index.round("min") # Indexの日時から1分に丸めた列を作る
print(df.groupby(["round_min", "action"]).size())
出力結果は以下のようになりました。
round_min action
2023-12-04 17:55:00+09:00 ALLOW 10
2023-12-04 17:56:00+09:00 ALLOW 277
2023-12-04 17:57:00+09:00 ALLOW 395
2023-12-04 17:58:00+09:00 ALLOW 140
2023-12-04 17:59:00+09:00 ALLOW 270
BLOCK 4
2023-12-04 18:00:00+09:00 ALLOW 106
2023-12-04 18:01:00+09:00 ALLOW 20
2023-12-04 18:02:00+09:00 ALLOW 61
2023-12-04 18:03:00+09:00 ALLOW 20
2023-12-04 18:04:00+09:00 ALLOW 25
2023-12-04 18:05:00+09:00 ALLOW 10
dtype: int64
17:59 の前後に 4 件の BLOCK が発生していることがわかります。
pandas の plot 機能(内部的には Matplotlib が使われている)を使い可視化します。
df.groupby(["round_min", "action"]).size().unstack().plot(kind="bar", stacked=True)
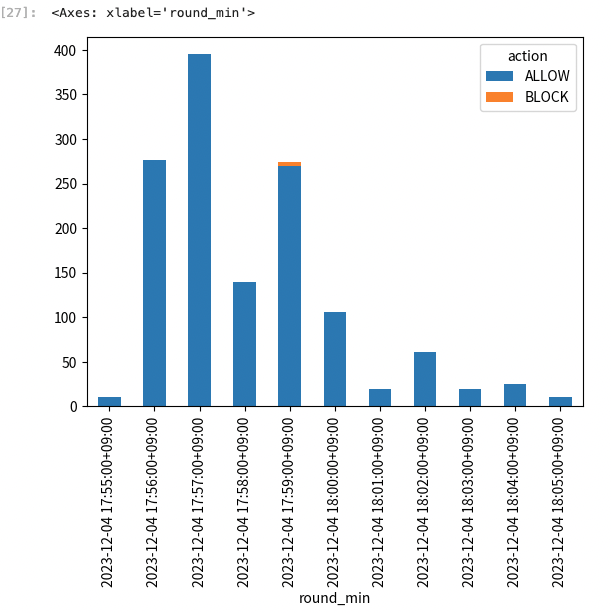
可視化することで、どのタイミングで BLOCK が発生しているのかが一目瞭然となりました。
BLOCK された IP アドレスの確認¶
BLOCK された IP アドレスを抽出し、それぞれの件数を確認します。
print(df_blocked.loc[:, "httpRequest.clientIp"].value_counts())
結果は以下の通りです。(IP アドレスの一部を xxx でマスクしています)
httpRequest.clientIp
52.xxx.xxx.247 2
1.xxx.xxx.213 1
240b:11:600:xxxx:xxxx:xxxx:xxxx:75e4 1
Name: count, dtype: int64
3 箇所の IP アドレスからアクセスがあり、1 つは 2 回アクセスがあり、他は 1 回のみのアクセスとなっていました。 この結果から同じ場所から大量にアクセスされていることはなく、何かしらの間違えでこの URL にアクセスされたのではないかと予想できます。 また、1 つの IP アドレスは IPv6 となっていました。アクセス制御を IPv4 で行なっている場合、接続元のネットワークが IPv6 をサポートしていて想定していない接続ルートになっている可能性があると考えられます。
BLOCK された前後のログを確認する¶
ここでは、IP アドレス 52.xxx.xxx.247 からのアクセスで BLOCK された、17:58:45 前後のログを抽出します。
df_one_ip = df.loc[df.loc[:, "httpRequest.clientIp"] == "52.xxx.xxx.247", :]
df_one_ip.loc[
"2023-12-04 17:58:40+09:00":"2023-12-04 17:58:50+09:00",
["action", "httpRequest.clientIp", "httpRequest.uri"]
]
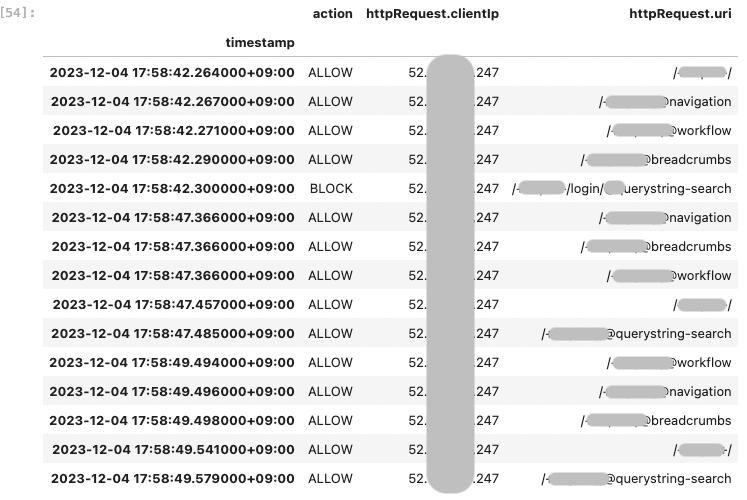
URL の一部をマスクしています。
前後の URL を見たところ、不正にアクセスしている様子は見受けられず、なにかしらの原因で login に関係する URL へのアクセスがされた模様です。URL を見て正常かどうかを判断するには、サイトの特性やどのようなアクセスが正常なのかを知っている必要があります。
Lambda から出力されるログを解析¶
ここからは AWS Lambda の動作ログを確認します。 定期実行される Lambda のログを CloudWatch Logs で確認します。構成は以下の通りです。
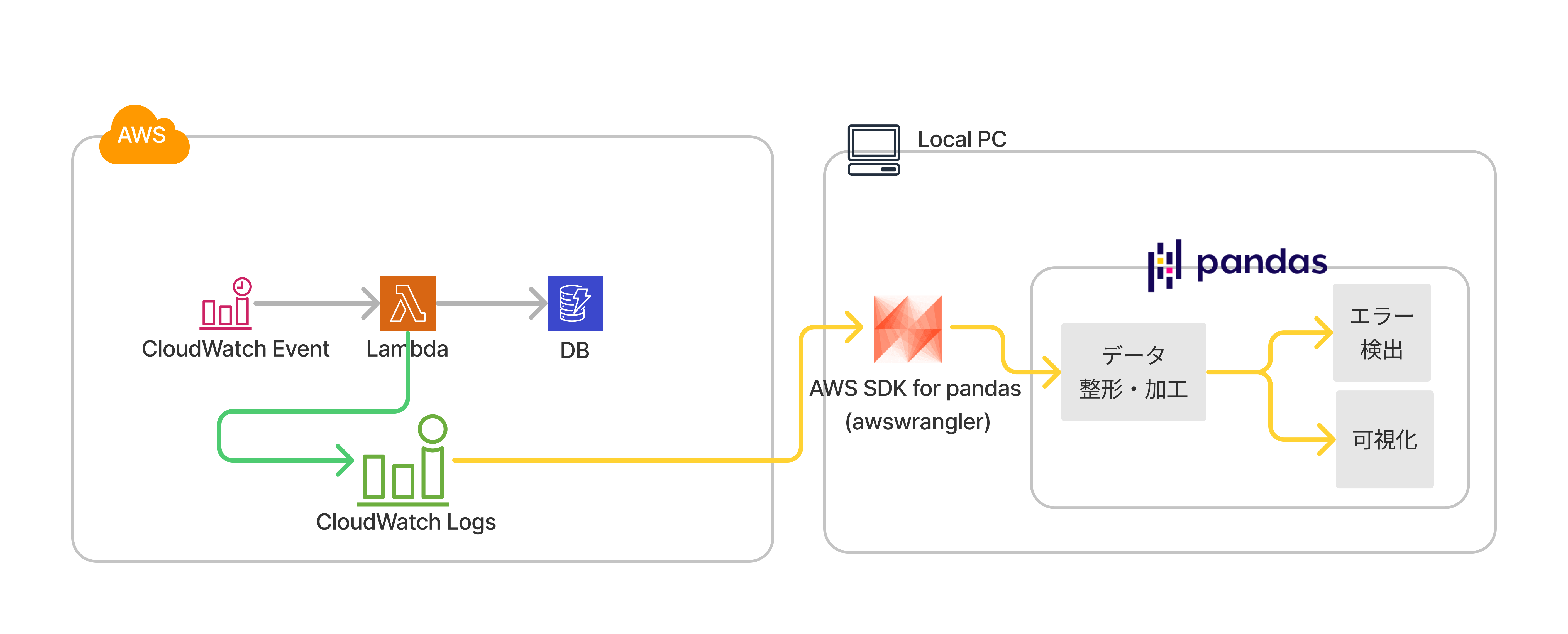
AWS Web コンソールでログを確認すると以下のように表示されます。WAF の時は JSON 形式で出力されましたが、Lambda はテキスト形式でログ出力されます。
Lambda の起動時に出力されるログと、コード内で出力しているログが混ざって出力されます。
ここでは、メッセージ(message)内に「error」と「warning」という文字列の件数をそれぞれ確認します。
AWS WAF で行なったのと同じ様に、必要なライブラリをインポートし、期間を指定して取得します。
今回は、Lambda が東京リージョンで動いているので、 region_name を変更しています。
次のコードで CloudWatch Logs からデータを取得し、DataFrame 化します。
import os
from datetime import datetime
from zoneinfo import ZoneInfo
import awswrangler as wr
import boto3
ASIA_TOKYO = ZoneInfo("Asia/Tokyo")
start = datetime(2023, 12, 4, 9, 0, 0, tzinfo=ASIA_TOKYO)
end = datetime(2023, 12, 4, 9, 15, 0, tzinfo=ASIA_TOKYO)
limit = 1000
region_name = "ap-northeast-1" # Lmabdaが実行されるリージョン 今回は東京
log_name = "/aws/lambda/dummy-xxxx-xxxxx"
boto3_session = boto3.session.Session(
aws_access_key_id=os.getenv("AWS_ACCESS_KEY"),
aws_secret_access_key=os.getenv("AWS_SECRET_KEY"),
region_name=region_name,
)
df_lambda_raw = wr.cloudwatch.read_logs(
log_group_names=[log_name],
query="fields @timestamp, @message | sort @timestamp asc",
limit=limit,
start_time=start,
end_time=end,
boto3_session=boto3_session,
)
print(df_lambda_raw.shape) # (37, 3)
AWS WAF 同様に、Index に aware な日時を設定します。
df = df_lambda_raw.loc[:, ["message"]]
df.index = df_lambda_raw.iloc[:, 0].dt.tz_localize("UTC").dt.tz_convert("Asia/Tokyo")
先頭の 5 件を表示すると以下のようになります。
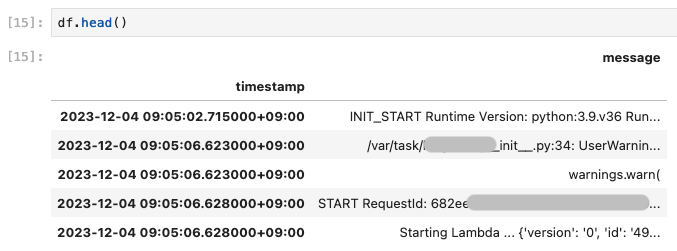
指定の文字列が含まれる件数を調べる¶
「error」と「warning」という文字列の件数を出力します。
print(df.loc[:, "message"].str.contains("error", case=False).sum()) # 出力結果「0件」
print(df.loc[:, "message"].str.contains("warning", case=False).sum()) # 出力結果「2件」
今回の例だと、「error」は 0 件、「warning」は 2 件ありました。
pandas の DataFrame の .str アクセサを使って、 contains() メソッドで指定の文字列が含まれている行を抽出しています。
その際に、 case=False とし、大文字・小文字を区別しないようにしています。
contains() メソッドの戻り値は、以下のように boolインデックス となります。
print(df.loc[:, "message"].str.contains("warning", case=False).iloc[:3])
timestamp
2023-12-04 09:05:02.715000+09:00 False
2023-12-04 09:05:06.623000+09:00 True
2023-12-04 09:05:06.623000+09:00 True
Name: message, dtype: boolean
今回は件数を知りたかったので、 sum() メソッドを使い、 True の数を出力しました。
メッセージ内の文字列の表示¶
今回のデータは、 warning が 2 件含まれていました。この内容を確認していきます。
df.loc[df.loc[:, "message"].str.contains("warning", case=False), "message"]
timestamp
2023-12-04 09:05:06.623000+09:00 /var/task/lxxxxxxxn/__init__.py:34: UserWarnin...
2023-12-04 09:05:06.623000+09:00 warnings.warn(
Name: message, dtype: string
2 行のデータを先ほど contains() メソッドで確認した bool インデックスを使い抽出しました。
ここでは、1 件目のデータの文字列を確認します。
print(df.loc[df.loc[:, "message"].str.contains("warning", case=False), "message"].iloc[0])
/var/task/lxxxxxxxn/__init__.py:34: UserWarning: Importing xxxxxxxx from xxxxxxxx root module is no longer supported. Please use xxxxxx.xxx.xxxxxxxxxx instead.
内容はマスクしましたが、利用できなくなっているモジュールがあるので別の物を利用するように警告が出ていました。
まとめ¶
今月は、AWS SDK for pandas (awswrangler) を使って、CloudWach Logs で出力されたログを、pandas で DataFrame 化して解析する例を紹介しました。 pandas は時系列データを取り扱う機能が豊富に揃っています。AWS のツールでログを解析する方法もありますが、Python や pandas に慣れている方からすると、さまざまなデータの取扱ができ、可視化や自動化など応用範囲が広がるのではないかと思っています。
みなさんも pandas でのログの分析に挑戦してみましょう。