2024年12月: 音声認識モデルWhisperで文字起こし¶
杉田 (@ane45) です。2024年12月の「Python Monthly Topics」は OpenAIの音声認識モデルWhisperをPythonから使用する方法を解説します。さらに、Whisperモデルを基にした派生ツールやライブラリであるwhisper.cpp、faster-whisper、mlx-whisperについても紹介します。
Whisperとは¶
Whisperは、多様な音声データを使ってトレーニングされた音声認識モデルです。このモデルは、多言語の音声認識、音声翻訳、言語識別を高精度で実行できます。 Whisperは、ChatGPTでおなじみのOpenAIが提供しており、MITライセンスのOSS版とAPI版があります。
Whisperの関連ドキュメントは以下を参照してください。
Whisperで利用可能なモデルと言語¶
Whisperで利用可能なモデルは6種類あり、全てのモデルに多言語モデルが用意されています。英語のみのモデルは一部のモデルに限られています。 これらのモデルは速度と精度のバランスを選べるよう設計されていて、Parameters の値が増えるにつれて精度が向上し、実行にかかる時間が増えていきます。 表に記載のある相対速度は、A100(GPU) で英語の音声を書き起こして測定されたもので、実際の速度は、言語、発話速度、利用可能なハードウェアなど、多くの要因によって異なる場合がありますので実際にはお手元の環境で試してみてください。
Size |
Parameters |
English-only model |
Multilingual model |
Required VRAM |
Relative speed |
|---|---|---|---|---|---|
tiny |
39 M |
|
|
~1 GB |
~10x |
base |
74 M |
|
|
~1 GB |
~7x |
small |
244 M |
|
|
~2 GB |
~4x |
medium |
769 M |
|
|
~5 GB |
~2x |
large |
1550 M |
N/A |
|
~10 GB |
1x |
turbo |
809 M |
N/A |
|
~6 GB |
~8x |
表の引用元: https://github.com/openai/whisper?tab=readme-ov-file#available-models-and-languages
Whisperを使ってみる¶
Whisperは、MITライセンスのOSS版とAPI版の利用が可能です。それぞれを利用する方法をみていきます。
以下は筆者の動作環境になります
M2 MacBook macOS Sonoma 14.7 メモリ 16GB
Python 3.11.5
OSS版がサポートするPythonバージョンは Python 3.8 〜 3.11 になります。
OSS版¶
OSS版のWhisperを利用するには、pipでインストールします。 また、動画と音声を記録・変換・再生するためのコマンドラインツールFFmpegが別途必要です。 FFmpegはほとんどのパッケージマネージャーから入手できますので、ご自身の環境にあった方法でインストールしてください。
Whisperでは音声データの読み取りにFFmpegを使用しているため、FFmpegが対応している音声形式であれば処理可能です。
% pip install openai-whisper
# FFmpegのインストール(Macの場合)
% brew install ffmpeg
以下は、Whisperのmediumモデルを使って音声データを文字起こしする例です。文字起こしにかかる時間を測定するために、timeモジュールを使って計測しています。
import time
import whisper
input_file = "voice_sample.m4a" # 音声データのファイルパス
model = whisper.load_model("medium") # 使用するモデルを指定する
start_time = time.time()
result = model.transcribe(input_file, fp16=False) # 音声データの文字起こし
end_time = time.time()
print(result["text"]) # 文字起こし結果の表示
print(f'実行時間: {end_time - start_time} seconds')
実行時に、モデルが使用する浮動小数点精度が実行環境でサポートされていない場合、UserWarning: FP16 is not supported on CPU; という警告が表示されます。 その場合は、transcribe()メソッドに fp16=False オプションを指定してください。
上記のコードを実行すると、文字起こしされたテキストがprint()関数で表示されます。 使用する音声ファイルは、以下の文章(Python 実践レシピ 1章 の冒頭部分) を60秒間読み上げたものです。また、意図的に途中で「あのー」や「えっと」といった意味のない言葉も含めています。

音声ファイルの内容¶
上記のプログラムを実行すると、次のような文字起こし結果が得られます(「音声ファイルの内容」と異なる部分は濃い緑で示されています。また、比較を分かりやすくするために手動で改行を追加しています)。 驚くほど高い精度で文字起こしが行われていることがわかります。

文字起こしされた内容¶
また、音声ファイルには「あのー」や「えっと」といった意味のない言葉も含まれていますが、Whisperはそれらを自動的に省いて文字起こししてくれます。 これはWhisperの便利な点です。
initial_prompt オプション¶
今回のケースでは「PIP」は「pip」、「エンシュアPIP」は「ensurepip」と正確に書き起こしてほしいところです。 そのような場合は、transcribe() メソッドに initial_prompt オプションを与えることで修正できることがあります。
# transcribe() にinitial_prompt オプションを与える
result = model.transcribe(
input_file, fp16=False,
initial_prompt="pip ensurepip です。ます。した。" # 半角スペースで区切る
)

initial_promptを与えた文字起こしの結果¶
再実行すると、「PIP」が「pip」に文字起こしされています。また、「エンシュアPIP」が「ensurepip」に修正された箇所もありますが、「演習は pip」となってしまった箇所もありました。 このように完全ではありませんが、専門用語の多い音声データの場合、initial_prompt を与えることは有用です。また、音声データによっては、文字起こしされたデータに句読点がついていない場合もあります。その場合は、initial_prompt に「です。ます。した。」のような文字を与えることで、句読点をつけることができます。
initial_prompt に与えられる文字数には244トークン[1]のみという制限があります。 また、現在の initial_prompt には課題があります。30秒ごとに1つ前のセグメントのデコード結果でプロンプトが上書きされるため、前の30秒内に出現しなかった言葉は次のプロンプトに反映されず、initial_prompt で与えた文字が適用されない場合があります。 しかし、現在この課題を解決するためのPRがあり議論されています。将来的には、音声ファイル全体に initial_prompt で与えた単語が適用されるようになるかもしれません。
largeモデルで文字起こし¶
import whisper
input_file = "voice_sample.m4a"
model = whisper.load_model("large") # largeモデルに変更
result = model.transcribe(input_file, fp16=False) # initial_promptはなし
print(result["text"])
以下はモデルをlargeに変更し、initial_promptは与えずに文字起こしをした結果です。 精度が上がり、かなり原文に近い形になっていることがわかります。

largeモデルを使用した文字起こしの結果¶
API版¶
API版では、large-v2 モデルを使用した、文字起こしと翻訳の2つのエンドポイントを提供しています。
利用方法¶
APIを利用するには、OpenAIのアカウントが必要です。また、最低5米ドルの残高をアカウントに入金し、クレジットカードを登録する必要があります。入金は以下の画面から行います。
試しに使ってみたい方は、自動チャージ機能をOFFにしておくと良いでしょう。
APIの料金¶
Whisperモデルを使用して音声からテキストへの変換を行う場合、音声の長さに基づいて料金が計算されます。音声の再生時間を基準に課金され、秒単位で切り上げられます。 料金に関しては以下の公式ドキュメントを参照してください。
Whisper $0.006 / minute (rounded to the nearest second)
現時点では、料金は1分ごとに0.006ドルです。日本円に換算すると、1時間の音声データの文字起こしで約54円ほどです。(1USドル150円換算) 料金は変更の可能性があるため、使用する際は最新の情報を確認してください。
APIキーの作成¶
APIを使用するためにAPIキーを作成します。APIキーの作成は用途によって異なりますが、ここではプロジェクト単位でAPIキーを発行します。以下のURLにアクセスし、APIキーを発行します(https://platform.openai.com/ でログインしておく必要があります)。
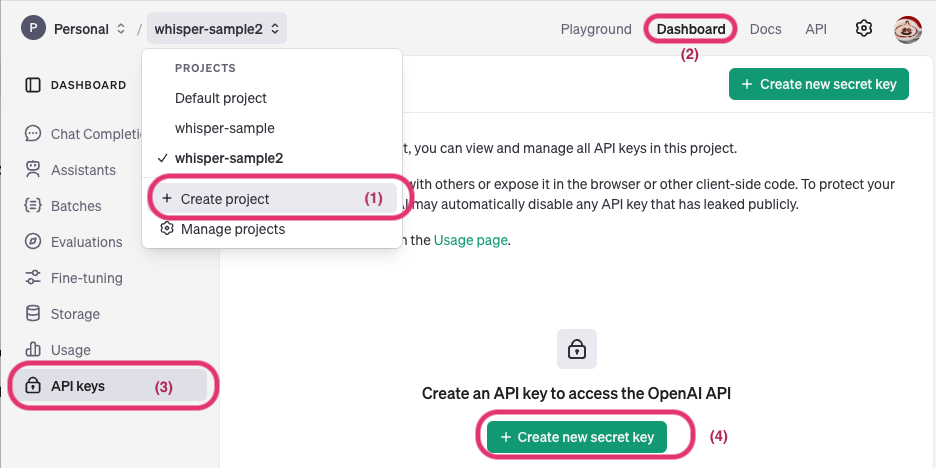
APIキーの発行¶
(1) 画面左上部の「Create project」をクリックし任意のプロジェクト名を入力します。
(2) 画面右上部の「Dashboard」をクリック
(3) 画面左メニューの「API Keys」をクリック
(4) 「create new secret key」をクリックしAPI key を発行します。
以下は、APIを使用して音声データをテキストに変換するサンプルコードです。取得したAPIキーは環境変数OPENAI_API_KEYとして設定しています。 API版のWhisperで対応している音声ファイル形式は以下の通りです。
mp3、mp4、mpeg、mpga、m4a、wav、webm
import os
from openai import OpenAI
api_key = os.getenv('OPENAI_API_KEY')
client = OpenAI(api_key=api_key)
# 音声ファイルをバイナリ読み取りモードで開きファイルオブジェクトを格納
audio_file = open('./voice_sample.m4a', 'rb')
# 音声ファイルをOpenAI APIに送信して文字起こしをリクエスト
transcription = client.audio.transcriptions.create(
model='whisper-1',
file=audio_file,
)
# 結果の文字起こしは変数に格納される
print(transcription)
上記を実行して得られた文字起こしの結果です。緑が濃くなっている箇所は「音声ファイルの内容」との差分になります。

API使用で文字起こしされた内容¶
APIには、以下のパラメータを指定することができます。
引数 |
説明 |
|---|---|
file |
audioファイルのオブジェクト |
model |
whisper-1 のみ使用可能 |
language |
入力言語 ISO-639-1フォーマットで指定することで精度があがる |
prompt |
複数指定したい場合は、カンマで区切る 244トークンのみ |
response_format |
出力の形式。json、text、srt、verbose_json、vttのいずれか |
temperature |
サンプリング温度。デフォルトは0 |
prompt は、OSS版で紹介した initial_promptと同じように利用できます
response_format はデフォルトはjsonで、verbose_jsonを指定するとより詳細な値を取得できます。 srtやvttはタイムコード付きの字幕データで、YouTubeなどにアップロードできる形式です。
temperatureは 0〜1の範囲で設定可能で、出力のランダムさを調整します。デフォルト値は0です。 値が高いほど多様的な応答が生成され、値が低いほど一貫性や正確性が高くなります。 文字起こしのような正確性が求められるタスクでは通常0の設定でよいでしょう。
ファイルサイズの制限¶
APIは25MB以下のファイルのみサポートしています。それ以上の長さの音声ファイルの場合は、25MB以下に分割するか、圧縮された音声形式を使用する必要があります。
以下でPyDubパッケージを使用して音声を分割する方法を紹介します。
https://github.com/jiaaro/pydub
PyDubはpipでインストールします。
% pip install pydub
以下は90秒の音声ファイルを30秒ごとに分割する例です。
from pydub import AudioSegment
audio = AudioSegment.from_file('voice_sample_90s.m4a', format='m4a')
# セグメントの長さを30秒に定義。ミリ秒単位で指定します
segment_duration = 30 * 1000
# 音声をスライスを使用してセグメントに分割します
segments = [audio[i:i + segment_duration] for i in range(0, len(audio), segment_duration)]
# 各セグメントを別々のファイルとしてエクスポート
for idx, segment in enumerate(segments):
segment.export(f'voice_sample_90s_part{idx + 1}.m4a', format='ipod')
また、PyDubのsplit_on_silenceという関数を使用すると、無音部分をカットすることが可能です。 上記では単純に30秒ごとにファイルを区切りましたが、より正確な文字起こしをしたい場合は、意味のある文で区切ることも大切です。その場合、例えば1秒の無音を文の区切りとして検出し、そこでファイルを区切るといった工夫もできます。
Whisperモデルの派生プロジェクト¶
Whisperの他に whisper.cpp, faster-whisper, mlx-whisper といった軽量化や高速化を目指した派生ツール・ライブラリも存在します。 これらは、OpenAIのWhisperモデルを基にしており、異なるニーズや制約に対応しています。
特徴 |
Whisper |
whisper.cpp |
faster-whisper |
mlx-whisper |
|---|---|---|---|---|
実装言語 |
Python |
C++ |
Python |
Python |
速度 |
標準 |
高速 |
非常に高速 |
高速 |
用途 |
汎用的 |
軽量環境 |
高速推論が必要な場合 |
Macに最適化 |
それぞれの特徴と使い方について解説します。
whisper.cpp¶
GitHubリポジトリ: https://github.com/ggerganov/whisper.cpp
whisper.cpp は、OpenAI の Whisper モデルをより軽量かつ高速に実行するための C++ ベースの実装です。以下の特徴があります。
Whisper モデルを ggml フォーマットに変換したものを使用することでメモリ使用量を最小限に抑えつつ、高速な計算を可能にします。
CPU のみで高い性能を発揮することが可能で、モバイルデバイスや組み込みシステムなどのリソースが限られた環境でも利用できます。
Windows、Linux、macOS だけでなく、Raspberry Pi や WebAssembly を含む多くの環境で動作します。
使い方¶
Whisper.cppは現状は16-bit のwavファイルのみに対応しています。 MP3 や M4A など他の形式の音声ファイルを使用する場合は、WAV 形式に変換する必要があります。 以下のように、FFmpeg を利用して簡単に変換できます。
% ffmpeg -i voice_sample.m4a -ar 16000 -ac 1 -c:a pcm_s16le voice_sample.wav
以下の手順でWhisper.cppをセットアップし、文字起こしを実行します。 Whisper.cppのビルドには、C/C++コンパイラ、make、およびCMakeが必要です。これらのツールはお使いの環境に応じてインストールしてください。
# 1. リポジトリをクローン
% git clone https://github.com/ggerganov/whisper.cpp.git
% cd whisper.cpp
# 2. モデルをダウンロード (large-v3を指定してダウンロード)
% sh ./models/download-ggml-model.sh large-v3
# 3. プロジェクトをビルド
% make # makeを実行すると、buildディレクトリの中にコンパイルされたwhisperが作成されます
# 4. 文字起こしを実行
% ./build/bin/main -m models/ggml-large-v3.bin -f voice_sample.wav -l ja
利用可能なモデルは以下で確認できます。
https://github.com/ggerganov/whisper.cpp/blob/master/models/README.md#available-models
faster-whisper¶
GitHubリポジトリ: https://github.com/SYSTRAN/faster-whisper
faster-whisper は、OpenAI の Whisper モデルを高速化した Python ベースの実装です。以下の特徴があります。
高速推論エンジンである CTranslate2 を使用し、オリジナルの Whisper に比べて最大4倍高速で動作するとされています。
メモリ使用量を削減しつつ、オリジナルモデルと同等の精度を実現しています。
Silero VAD を利用することで、無音部分を除去し、文字起こし精度を向上できます。
使い方¶
pipでインストールします。
% pip install faster-whisper
faster-whisperはCUDA対応のGPUを使用した高速化をサポートしていますが、CPUでも動作します。 筆者のローカル環境では、CUDA対応のGPUがないため、GPUを活用できません。このため、以下のサンプルはdevice=cpuを設定して、CPUでの実行としています。
以下は、音声ファイルを文字起こしする簡単なサンプルコードです。
from faster_whisper import WhisperModel
audio_path = 'voice_sample.m4a'
# device='cpu'は CPU で動作させる設定(CUDA 対応 GPU を使用する場合は 'cuda' を設定する)
model = WhisperModel('large-v3', device='cpu')
segments, info = model.transcribe(audio_path, beam_size=5)
for segment in segments:
print(f'[{segment.start:.2f}s - {segment.end:.2f}s] {segment.text}')
以下の表に、transcribe メソッドで使用できる主なパラメータをまとめました。
パラメータ |
説明 |
|---|---|
audio |
音声ファイルのパスまたはファイルオブジェクト |
beam_size |
ビームサーチのサイズ(デコード精度に影響) |
language |
入力言語 ISO-639-1フォーマットで指定 |
without_timestamps |
タイムスタンプを含まない出力を生成(デフォルトFalse) |
vad_filter |
無音部分をフィルタリングし、文字起こしから除外(True で有効) |
無音部分をフィルタリングする場合(vad_filter=True)、デフォルトでは2秒以上の無音部分が除去されます。 この動作をカスタマイズするには、以下のように vad_parameters を設定します。
vad_parameters = {'min_silence_duration_ms': 500} # 無音部分の最小時間を500msに設定
segments, info = model.transcribe(
audio_path, beam_size=5,
vad_filter=True, vad_parameters=vad_parameters
)
無音検知には Silero VAD ライブラリが使用されており、より詳細な設定については以下をご覧ください。
GitHubリポジトリ: https://github.com/snakers4/silero-vad
mlx-whisper¶
mlx-whisper は、Apple Silicon に最適化された機械学習フレームワーク MLX を活用し、OpenAI の Whisper モデルを高速かつ効率的に実行するためのライブラリです。 MLX により、Apple 製デバイスでの音声文字起こしを高いパフォーマンスで処理できるよう設計されています。 MLX の詳しい情報利用方法は、公式リポジトリ https://github.com/ml-explore/mlxをご覧ください。
使い方¶
pipでインストールします。
% pip install mlx-whisper
# 以下のコマンドで、音声ファイルの文字起こしを簡単に実行できます.。
% mlx_whisper voice_sample.wav
以下は、Python から音声ファイルを文字起こしする簡単なサンプルコードです。
import mlx_whisper
audio_data = 'voice_sample.m4a'
# path_or_hf_repoには、使用するモデルを指定します
result = mlx_whisper.transcribe(
audio_data, path_or_hf_repo="mlx-community/whisper-large-v3-mlx"
)
print(result[text])
path_or_hf_repoで指定する利用可能な MLX 対応モデルは以下Hugging Face Hub[2] で確認できます。
指定がない場合は、デフォルトで mlx-community/whisper-tiny が使用されます。
処理時間の比較¶
以下は、筆者のローカル環境(上記に記載)で、30分間の音声データを文字起こしする際にかかる処理時間を計測した結果です。 計測結果は、文字起こしにかかる時間を分単位で比較しています。
model |
Whisper(OSS) |
whisper.cpp |
faster-whisper(CPU) |
mlx-whisper |
|---|---|---|---|---|
large-v3 |
31分 |
23分6秒 |
19分 |
13分1秒 |
large-v3-turbo |
9分11秒 |
8分2秒 |
6分21秒 |
3分36秒 |
large-v3-turboは、large-v3 モデルのデコーダー層を32層から4層に削減したモデルです。精度においてわずかな劣化が見られる場合もありますが、その代わりに高速化を実現しており、処理速度を重視する用途に適しています。
Whisper APIと Google Colaboratory(GPU)での測定結果です。
model |
Whisper(API) |
faster-whisper(GPU) |
|---|---|---|
large-v2 |
1分30秒 |
3分6秒 |
faster-whisper (GPU)
筆者のローカル環境では、CUDAを使用できないため、Google Colaboratory の無料枠である T4 GPU を使用しました。現時点のT4 GPUの環境は CUDA 12 + cuDNN 8 をサポートしていますが、最新版の CTranslate2 は CUDA 12 + cuDNN 9 を要求するため、faster-whisperのバージョン 0.10.0 を利用することで動作確認を行いました。
ローカル環境にて large-v3 モデル を使用しても、そこまでストレスなく文字起こしを実行できました。 特に筆者の環境においては、mlx-whisperが高速であり、他のモデルと比べて優れたパフォーマンスを発揮しました。
まとめ¶
今回は、OpenAIのWhisper、そのOSS版、API版を利用したPythonでの文字起こし方法、さらにWhisperの派生ツールであるwhisper.cpp、faster-whisper、mlx-whisperについて紹介しました。
Whisperを使うことで、多少の誤りはあるものの、音声の文字起こしで一から書き起こすよりも大幅に工数を削減できます。この技術は、議事録作成やメモ取り、インタビューの文字起こし、字幕の作成など、さまざまな場面で非常に役立ちます。さらに、Whisperで文字起こししたテキストをChatGPTなどにかけて、まとめや校正を行うことも可能です。
これからWhisperの精度はますます向上していくことが期待されています。進化し続けるこの技術を活用することで、今後さらに高精度で効率的な文字起こしが可能になるでしょう。
ぜひ、みなさんも活用してみてください。